Introduction to Graphical Causal Inference
From Averages to Heterogeneity

Humboldt-Universität zu Berlin
March 10, 2026
A Linear SCM with Interaction
Structural Equations
\begin{aligned} Z &= U_Z \\ X &= \beta^{XZ} Z + U_X \\ Y &= \beta^{YX} X + \beta^{YZ} Z + \textcolor{#D55E00}{\beta^{YXZ} XZ} + U_Y \end{aligned}
Distributional Assumptions
\begin{pmatrix} U_Z \\ U_X \\ U_Y \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} 0 \\ 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma^2_Z & 0 & 0 \\ 0 & \sigma^2_X & 0 \\ 0 & 0 & \sigma^2_Y \end{pmatrix}\right)

Graph Surgery: Interaction Case
Structural Equations
\begin{aligned} Z &= U_Z \\ X &= \color{#107895}{x} \\ Y &= \beta^{YX} \textcolor{#107895}{x} + \beta^{YZ} Z + \textcolor{#D55E00}{\beta^{YXZ} \textcolor{#107895}{x} Z} + U_Y \end{aligned}
Distributional Assumptions
\begin{pmatrix} U_Z \\ \textcolor{lightgray}{U_X} \\ U_Y \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} 0 \\ \textcolor{lightgray}{0} \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma^2_Z & 0 & 0 \\ 0 & \textcolor{lightgray}{\sigma^2_X} & 0 \\ 0 & 0 & \sigma^2_Y \end{pmatrix}\right)

Backdoor criterion: condition on Z. Done?
But Z = school is not a variable — it’s a cluster.
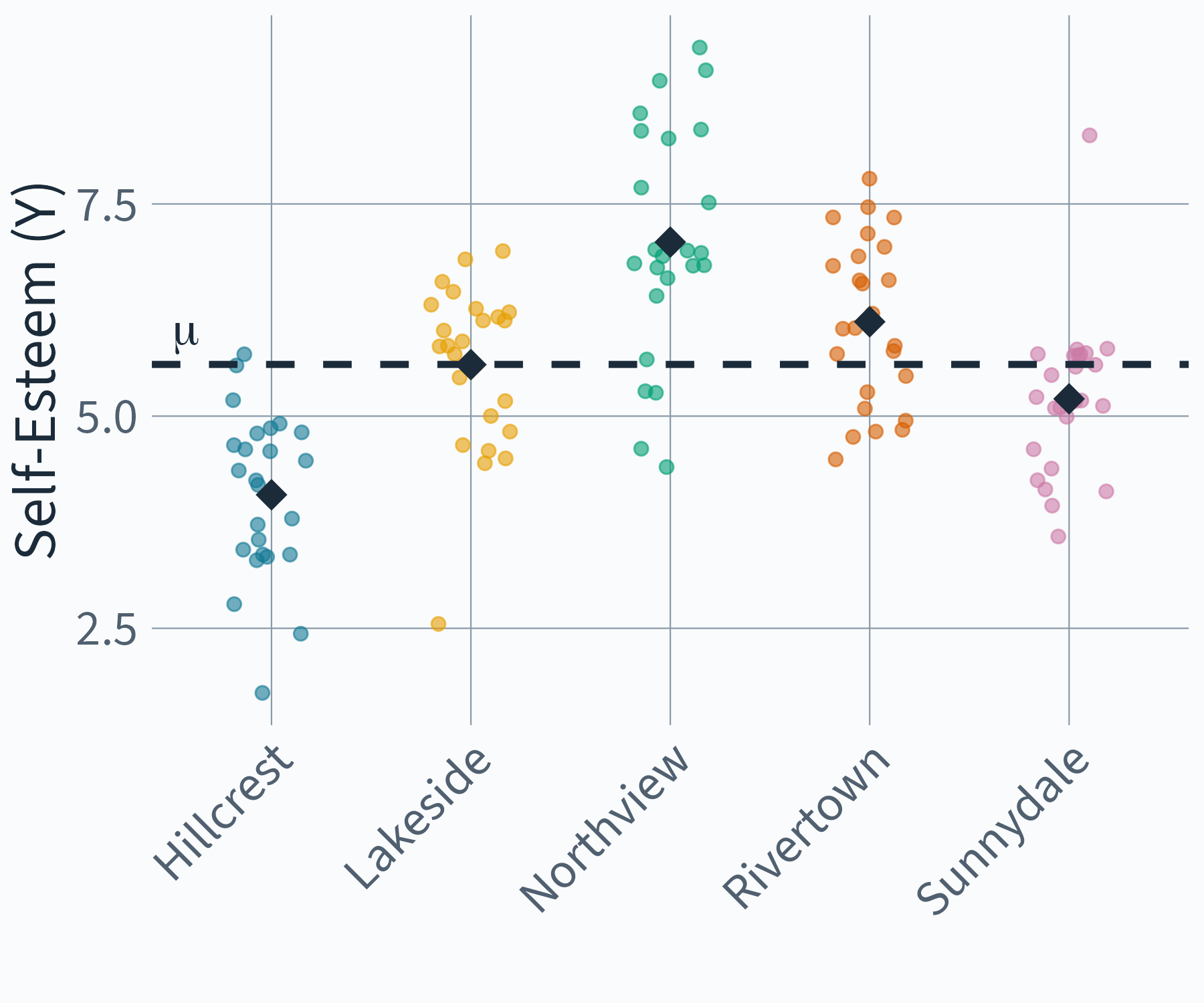
Random Intercept Model
\begin{aligned} y_{ij} &= \eta_{0j} + e_{ij} \\ \eta_{0j} &= \mu + u_{0j} \end{aligned}
Random Intercept Model
\begin{aligned} y_{ij} &= \mu + u_{0j} + e_{ij} \end{aligned}
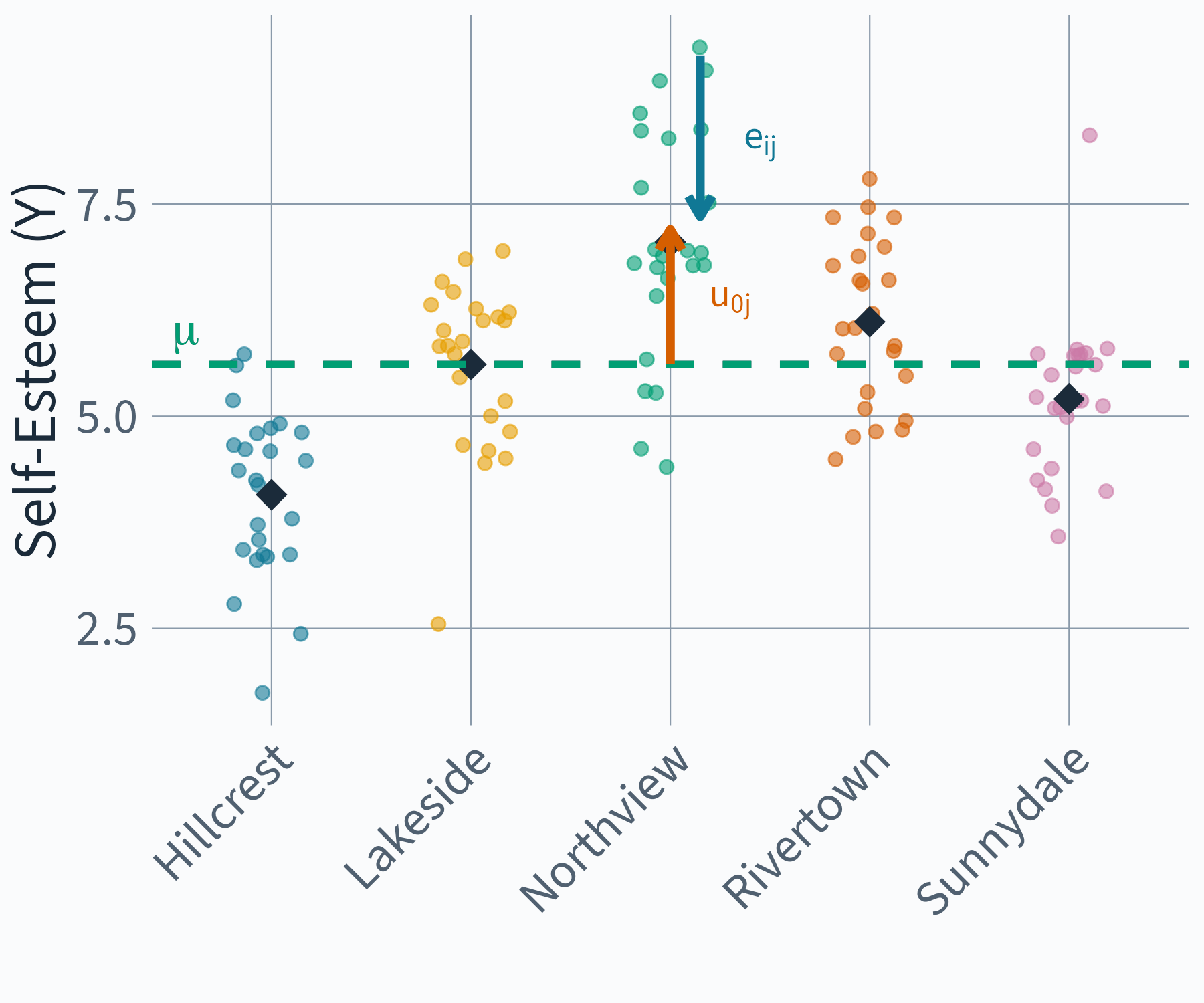
Random Intercept Model
\begin{aligned} y_{ij} &= \color{#009E73}{\mu}\color{black} + \color{#D55E00}{u_{0j}}\color{black} + \color{#107895}{e_{ij}}\color{black} \end{aligned}
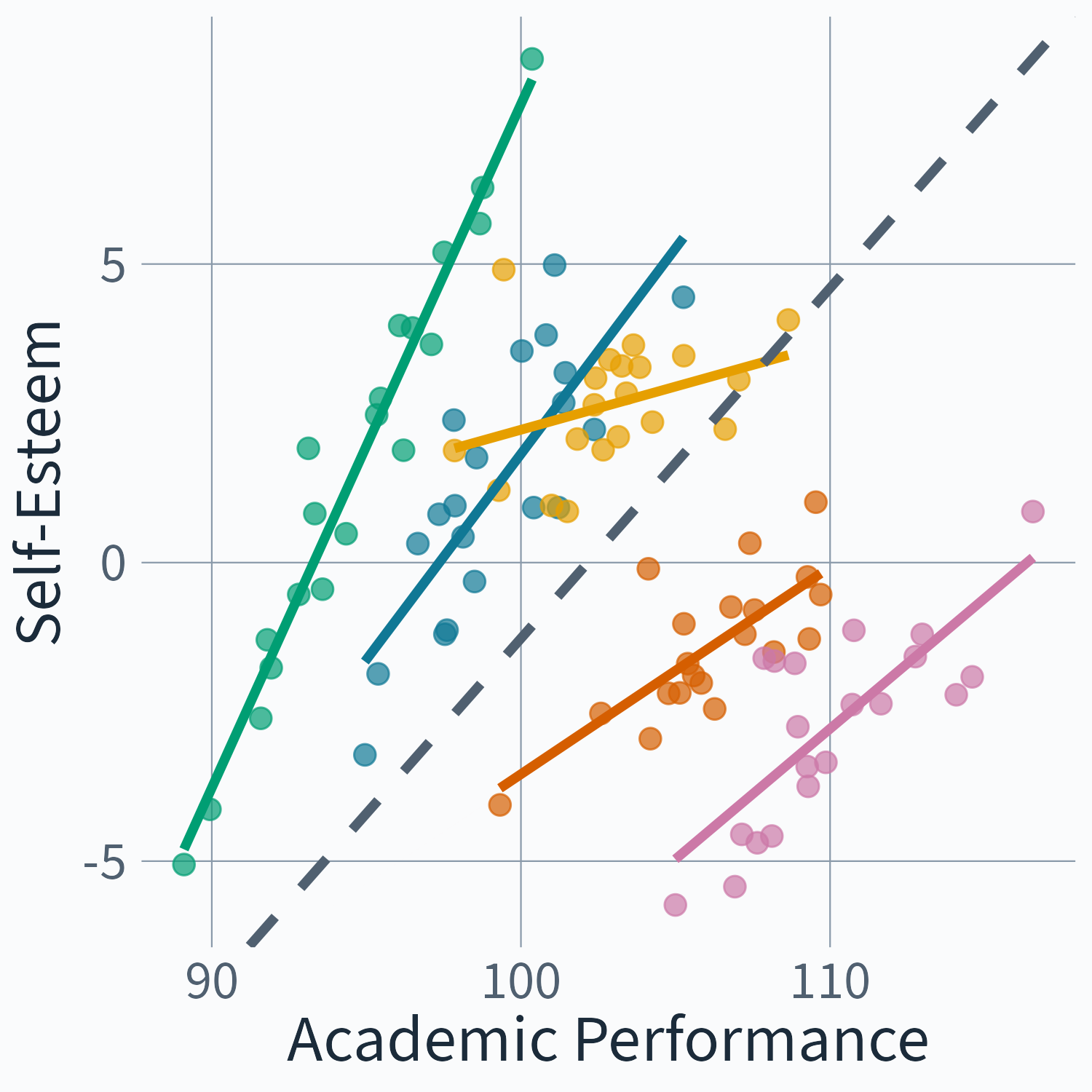
Multi-Level Notation
\begin{aligned} y_{ij} &= \eta_{0j} + \eta_{1j}x_{ij} + e_{ij} \\ \eta_{0j} &= \mu + u_{0j} \\ \eta_{1j} &= \beta + u_{1j} \end{aligned}
Back to our example
Structural Equations
\begin{aligned} Z &= U_Z \\ X &= \beta^{XZ} Z + U_X \\ Y &= \beta^{YX} X + \beta^{YZ} Z + U_Y \end{aligned}
Distributional Assumptions
\begin{pmatrix} U_Z \\ U_X \\ U_Y \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} 0 \\ 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma^2_Z & 0 & 0 \\ 0 & \sigma^2_X & 0 \\ 0 & 0 & \sigma^2_Y \end{pmatrix}\right)
What if Z is unobserved?
Structural Equations
\begin{aligned} \color{lightgray} Z &\color{lightgray}= U_Z \\ X &= \beta^{XZ} \textcolor{lightgray}{Z} + U_X \\ Y &= \beta^{YX} X + \beta^{YZ} \textcolor{lightgray}{Z} + U_Y \end{aligned}
Distributional Assumptions
\begin{pmatrix} \textcolor{lightgray}{U_Z} \\ U_X \\ U_Y \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} \textcolor{lightgray}{0} \\ 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \textcolor{lightgray}{\sigma^2_Z} & 0 & 0 \\ 0 & \sigma^2_X & 0 \\ 0 & 0 & \sigma^2_Y \end{pmatrix}\right)

Directed Acyclic Mixed Graphs
Structural Equations
\begin{aligned} X &= E^X \\ Y &= \beta^{YX} X + E^Y \end{aligned}
Distributional Assumptions
\begin{pmatrix} E^X \\ E^Y \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma^2_X & \textcolor{#D55E00}{\sigma_{XY}} \\ \textcolor{#D55E00}{\sigma_{XY}} & \sigma^2_Y \end{pmatrix}\right)

Directed Acyclic Mixed Graphs
Structural Equations
\begin{aligned} X &= E^X \\ Y &= \beta^{YX} X + E^Y \end{aligned}
Distributional Assumptions
\begin{pmatrix} E^X \\ E^Y \end{pmatrix} \sim \mathcal{N}\left(\begin{pmatrix} 0 \\ 0 \end{pmatrix}, \begin{pmatrix} \sigma^2_X & \textcolor{#D55E00}{\sigma_{XY}} \\ \textcolor{#D55E00}{\sigma_{XY}} & \sigma^2_Y \end{pmatrix}\right)

Plate Notation

From Independent to Dependent Units
